KSU Research Experience
Developing a Robust Deep Learning Model to Recognize Handwritten Text
Abstract and Research Map
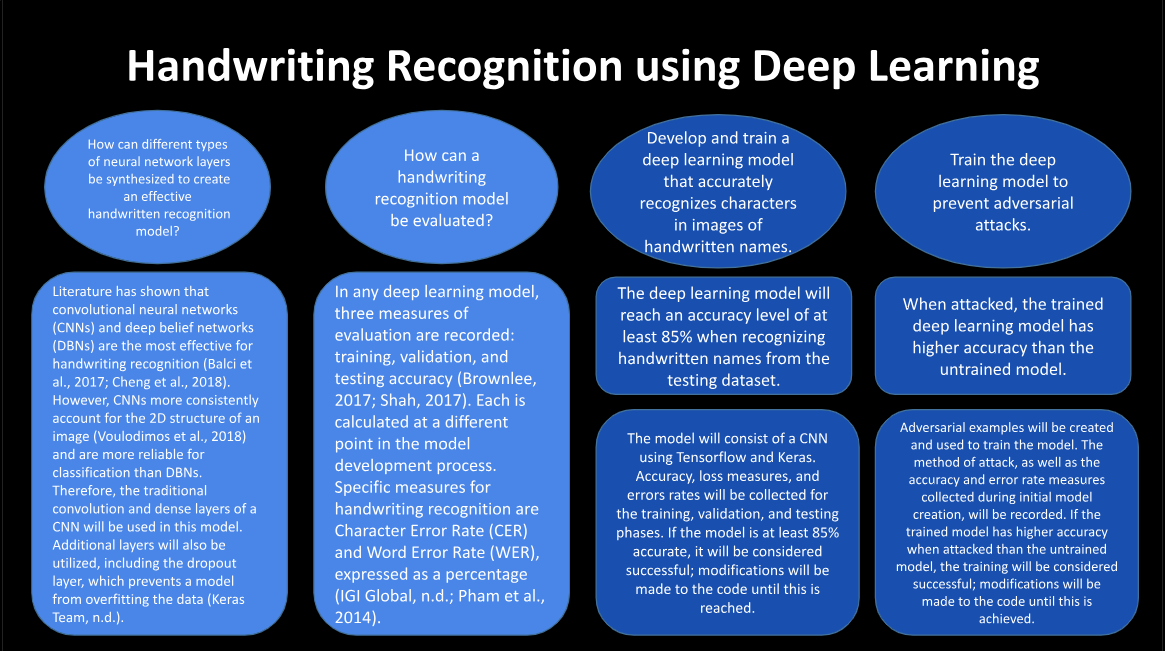
In recent decades, advances in computing have instilled in society a drive to streamline daily tasks, specifically through artificial intelligence and machine learning (IBM Cloud Education, 2020). One notable field facing an influx of machine learning solutions is handwriting recognition. Handwriting recognition is a subset of image recognition and involves converting text from handwritten documents to digital text (Aneja et al., 2021; Balci et al., 2017). Current models used to recognize handwritten text use a deep learning approach, mainly through Convolutional Neural Network (CNN) architectures (Shivanna et al., 2020). However, many models still encounter challenges in generalization and robustness. With generalization, current models struggle to recognize different handwriting styles (Cheng et al., 2018), and their architecture makes them more vulnerable to adversarial attacks (Deoras, 2020; Jain, 2019; Steenbrugge, 2018). Literature has indicated that character segmentation and adversarial training are effective at making these models more generalizable and resistant to attack (Aneja et al., 2021; Balci et al., 2017). However, research combining these respective solutions is relatively limited. This study aimed to help solve this problem and contribute to existing research in handwriting recognition. A deep learning model for handwriting recognition was constructed with a CNN-based architecture and showed a final accuracy of 93.20%. The Character Error Rate (CER) and Word Error Rate (WER) supplemented this accuracy, with final percentages falling well below the established thresholds of 10% and 40%, respectively. After the model was developed, it was attacked and trained against the Fast Gradient Sign Method (FGSM). Before training, the model's accuracy ranged from 14.11% to 62.30%, but its post-training accuracy consistently improved by more than 30%. The study's results support the efficacy of the model, which can be further improved upon and defended in order to be applied to real-world scenarios like reading medical forms or digitizing written notes.
Summarized Findings
Preprocessing + Model Development
Before the deep learning model was created, the images in the training, testing, and validation datasets used for the study were preprocessed. The number of images in each dataset was reduced due to limitations of the Google Colaboratory platform and the segmentation function. Next, the first prototype of the model was constructed after referencing three previously developed constructions, including ResNet50 and VGG16. After development, the model was first assessed on the validation data. For both the validation and testing data, the accuracy as well as the Character Error Rate (CER) and Word Error Rate (WER) of the model were collected. Based on these values, iterations were made to the model prototype. After the threshold values were met on the validation set, the model was assessed on the testing dataset (see table below). The model was considered a success when it met the following thresholds on the validation and testing datasets:
- ≥ 85% overall accuracy
- ≤ 10% Character Error Rate (CER)
- ≤ 40% Word Error Rate (WER)
| Dataset | Accuracy | Character Error Rate | Total Number of Names | Word Error Rate |
|---|---|---|---|---|
| Validation | 92.92% | 7.08% | 6,015 | 27.86%% |
| Testing | 93.20% | 6.80% | 15,867 | 26.24% |
Adversarial Attack & Subsequent Training
Finally, the model was attacked using the Fast Gradient Sign Method (FGSM) and then adversarially trained. Images generated with epsilon perturbation values ranging from ε = 0.1 to ε = 0.5 were assessed. Next, the model was trained on images generated with a perturbation of ε = 0.1 (see table below). The model was considered robust if its accuracy after adversarial training increased at least 10% for the ε = 0.1 image dataset when compared to the accuracy of the model before adversarial training.
The adversarial training process was considered a success, as the model's accuracy for the ε = 0.1 image dataset after training increased by more than 30% in comparison to the accuracy before training. Interestingly, this robustness also expanded to more severely perturbed epsilon values, as shown in the table below.
| Epsilon Value | Accuracy Before Adversarial Training | Accuracy After Adversarial Training |
|---|---|---|
| ε = 0.1 | 62.30% | 95.72% |
| ε = 0.15 | 57.48% | 95.80% |
| ε = 0.25 | 41.50% | 94.90% |
| ε = 0.5 | 14.11% | 72.39% |
Conclusions and Implications
This study aimed to determine how an effective and robust deep neural network for handwriting recognition can be built, evaluated, and defended against adversarial attacks. A deep learning model was developed to classify handwritten text and generate word predictions. Character segmentation and adversarial training were found to be effective in helping generalizability and robustness, so these methods were employed in the study. The validation and testing data assessments conducted indicate that the model was successfully developed, as the model's classification accuracy on both the character datasets was nearly 10% higher than the threshold measure of success. The adversarial training process was also successful; the post-training accuracy was more than 30% higher than the pre-training accuracy of the model at ε = 0.1. The model displayed similar increases in accuracy for higher epsilon values and more severe perturbations, indicating that it was trained to defend against the FGSM across numerous variations of the attack.
Despite the model's success, one unexpected characteristic of the images in this study was the presence of form-field names, such as printed characters. While a cropping function was used to remove these form fields from each component image, utilizing the function, along with the segmentation method, to iterate through thousands of images was time-consuming. Perhaps a new algorithm could be developed to automatically ignore common form field names, thus reducing the effort required for pre-processing each image. The improvement of the cropping and segmentation process in the study could lead to future research on and trends garnered from the dataset, as the function would be able to recognize and classify more characters in different styles of writing.